문자열
공식적으로, 문자열은 리터럴 상수 또는 일부 변수 유형을 나타내는 문자 시퀀스입니다. 비공식적으로는 프로그래밍에서 텍스트를 의미하는 용어입니다. 지금까지 정수 및 십진수를 사용하여 매개변수를 구동했으며, 텍스트로도 같은 작업을 수행할 수 있습니다.
문자열 작성
문자열은 사용자 매개변수 정의, 문서 세트에 주석 달기, 텍스트 기반 데이터 세트 구문 분석 등 광범위한 응용 분야에서 사용할 수 있습니다. 문자열 노드는 코어>입력 카테고리에 있습니다.

위의 샘플 노드는 문자열입니다. 숫자는 문자열로 나타내거나 문자 또는 전체 텍스트 배열로 나타낼 수 있습니다.
문자열 조회
이 연습과 함께 제공되는 예시 파일(프로그램의 빌딩 블록 - Strings.dyn)을 다운로드하십시오(마우스 오른쪽 버튼을 클릭하고 "다른 이름으로 링크 저장..." 선택). 전체 예시 파일 리스트는 부록에서 확인할 수 있습니다.
문자열을 조회하여 많은 양의 데이터를 신속하게 구문 분석할 수 있습니다. 워크플로우 진행 속도를 높이고 소프트웨어 상호 운용성을 지원하는 몇 가지 기본 작업에 대해 살펴보겠습니다.
아래 이미지에서는 외부 스프레드시트에서 들어오는 데이터 문자열을 고려합니다. 해당 문자열은 XY 평면에서 직사각형의 정점을 나타냅니다. 일부 문자열 분할 작업을 소규모 연습으로 나눠보겠습니다.
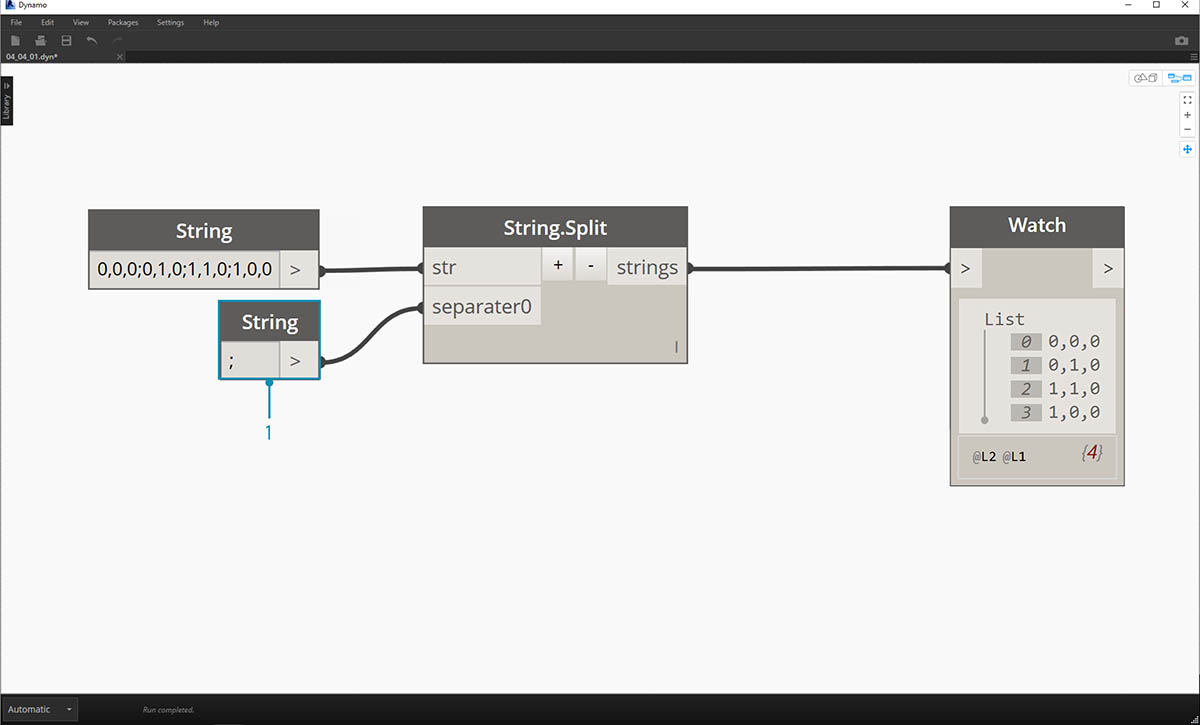
- ";" 구분 기호는 직사각형의 각 정점을 분할합니다. 그러면 각 정점에 해당하는 4개의 항목이 포함된 리스트가 작성됩니다.
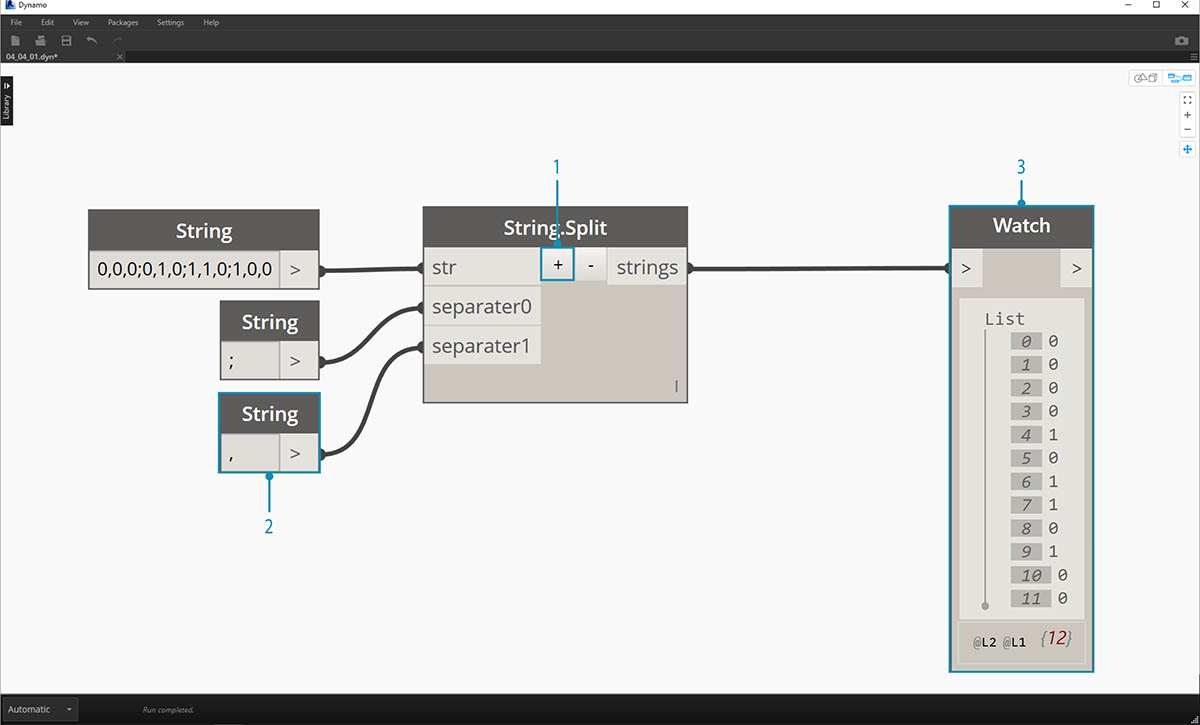
- 노드의 중간에 있는 "+"를 눌러 새 구분 기호를 작성합니다.
- "," 문자열을 캔버스에 추가하고 새 구분 기호 입력에 연결합니다.
- 이제 결과는 항목 10개로 구성된 리스트가 됩니다. 노드는 먼저 separator0을 기준으로 분할된 후 separator1을 기준으로 분할됩니다.
위의 항목 리스트는 숫자처럼 보일 수 있지만 Dynamo에서는 여전히 개별 문자열로 간주됩니다. 점을 작성하려면 해당 데이터 유형을 문자열에서 숫자로 변환해야 합니다. 이 작업은 String.ToNumber 노드를 사용하여 수행합니다.
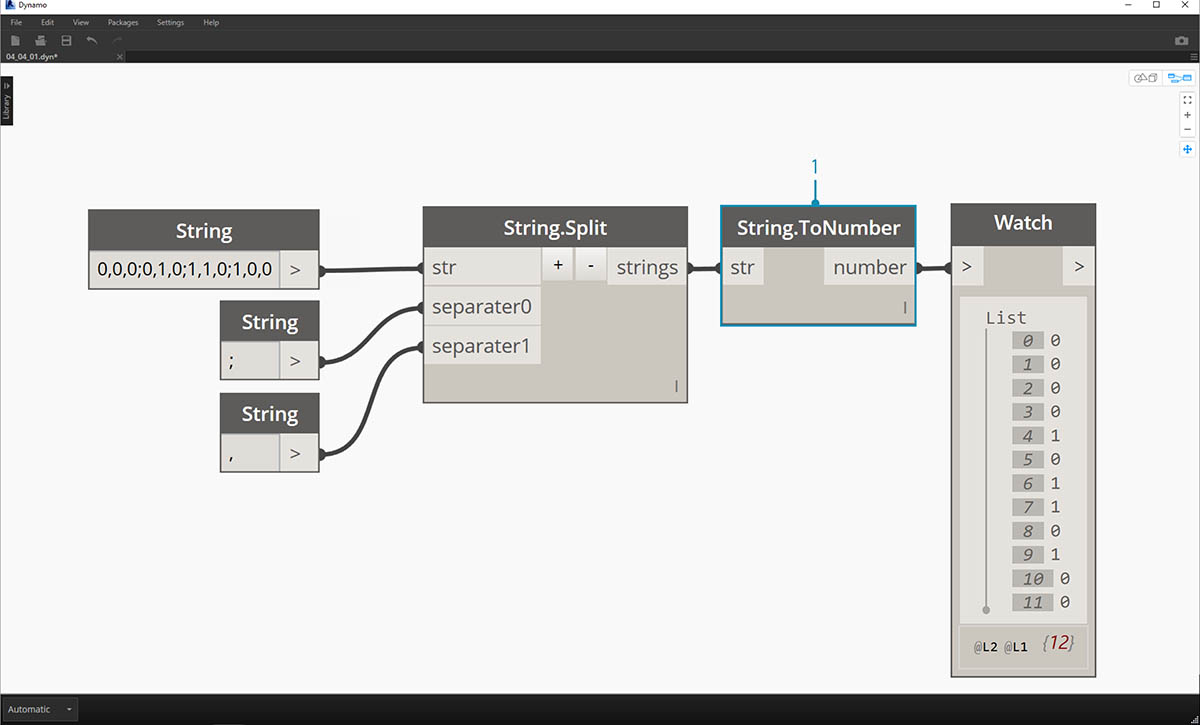
- 이 노드는 간단합니다. String.Split 결과를 입력에 연결합니다. 출력이 다르게 보이지는 않지만 데이터 유형은 이제 문자열이 아닌 숫자입니다.
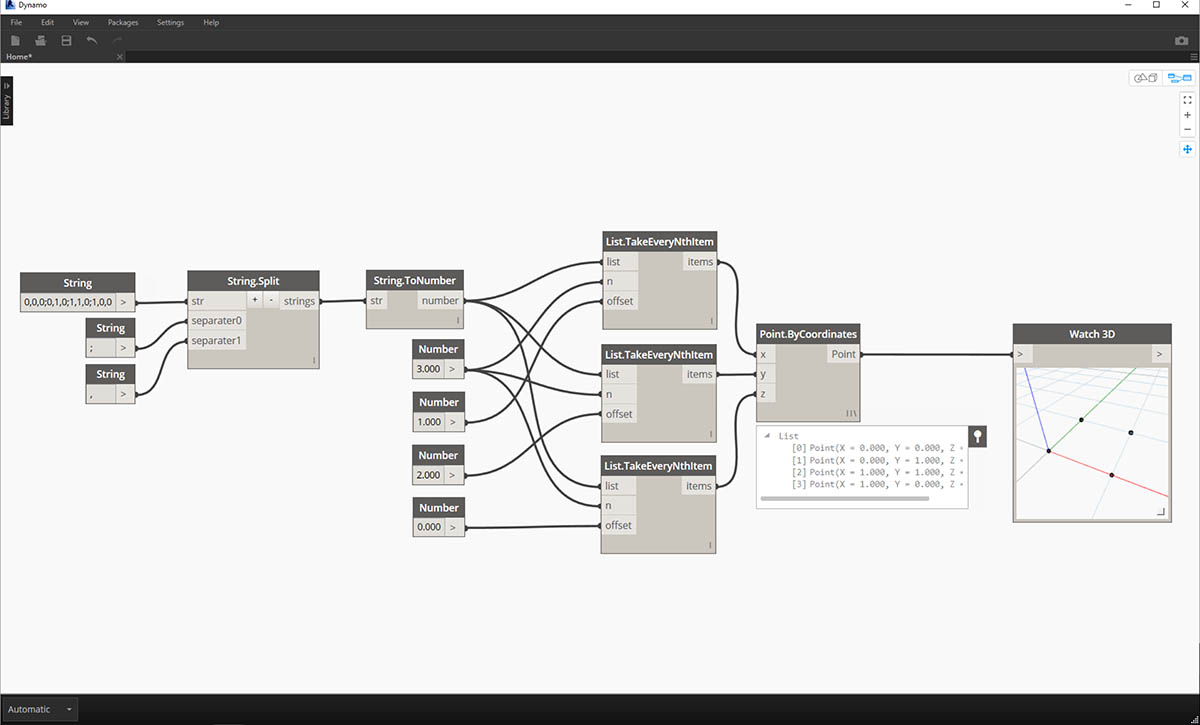
- 기본적인 추가 작업을 통해 원래 문자열 입력을 기준으로 원점에 직사각형이 그려집니다.
문자열 조작
문자열은 일반 텍스트 객체이므로 광범위한 응용 분야에서 사용됩니다. Dynamo의 코어>문자열 카테고리에 해당하는 몇 가지 주요 작업을 살펴보겠습니다.
다음은 두 문자열을 순서대로 병합하는 방법입니다. 이 방법에서는 리스트의 각 리터럴 문자열을 가져와 병합된 하나의 문자열을 작성합니다.
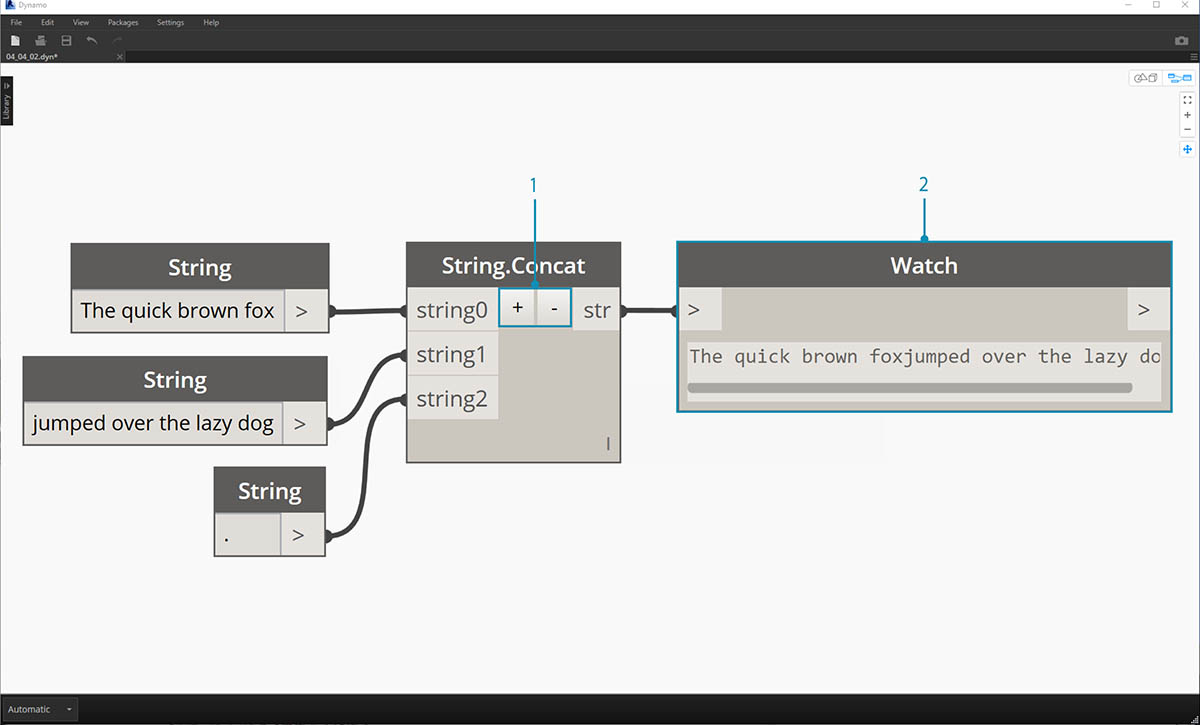
위의 이미지에는 다음 세 개의 문자열을 연결하는 과정이 나와 있습니다.
- 노드 중심에서 +/- 버튼을 클릭하여 연결 항목에 문자열을 추가하거나 연결 항목에서 문자열을 뺍니다.
- 출력에서는 공백과 문장 부호가 포함된 연결된 1개의 문자열이 제공됩니다.
결합 방법은 문장 부호가 하나 더 추가된다는 점을 제외하고는 연결과 매우 유사합니다.
Excel에서 작업한 경우 CSV 파일을 보았을 수 있습니다. CSV는 쉼표로 구분된 값을 의미합니다. 비슷한 데이터 구조 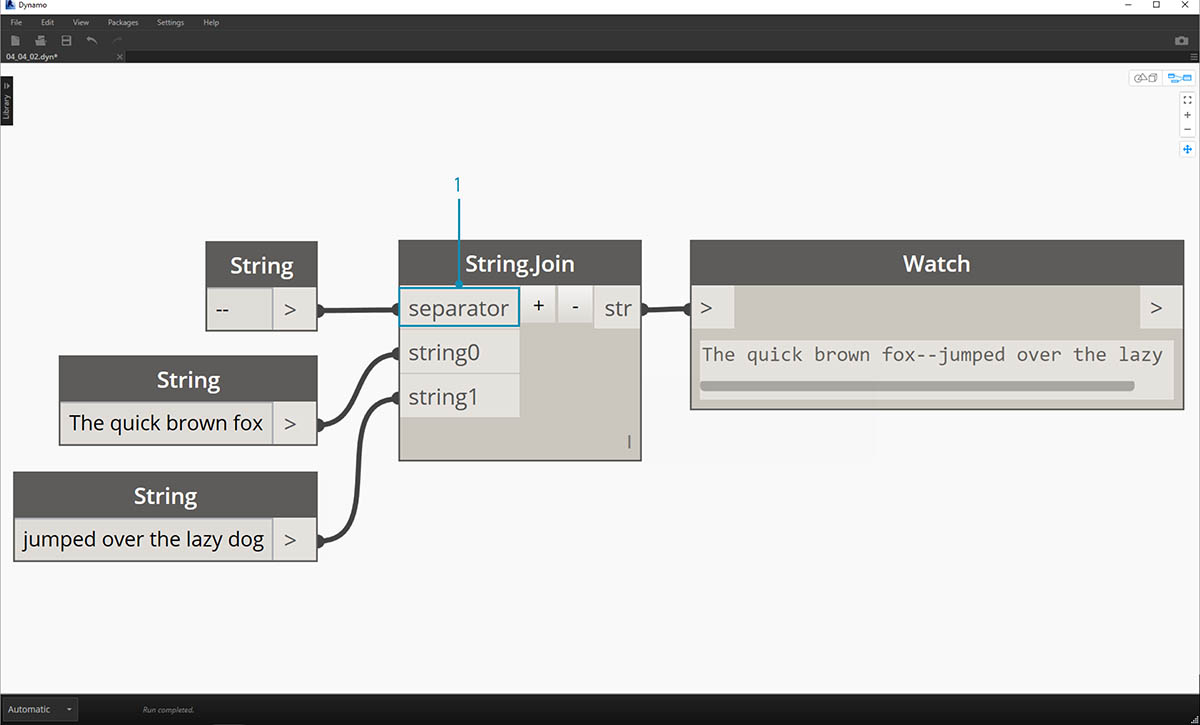 를 작성하기 위해 결합 노드에서 쉼표(또는 이 경우 두 개의 대시)를 구분 기호로 사용할 수 있습니다.
를 작성하기 위해 결합 노드에서 쉼표(또는 이 경우 두 개의 대시)를 구분 기호로 사용할 수 있습니다.
위의 이미지에는 두 개의 문자열의 결합하는 과정이 나와 있습니다.
- 구분 기호 입력을 통해 결합된 문자열을 분할하는 하나의 문자열을 작성할 수 있습니다.
문자열 작업
이 연습에서는 문자열을 조회하고 조작하는 방법을 사용하여 Robert Frost가 쓴 Stopping By Woods on a Snowy Evening(눈 내리는 저녁 숲가에 서서)의 마지막 절을 분석해 보겠습니다. 이러한 방법이 가장 실질적인 응용 사례는 아니지만, 명확한 리듬과 운율이 있는 줄에 적용할 경우 개념적 문자열 동작을 파악하는 데 도움이 됩니다.
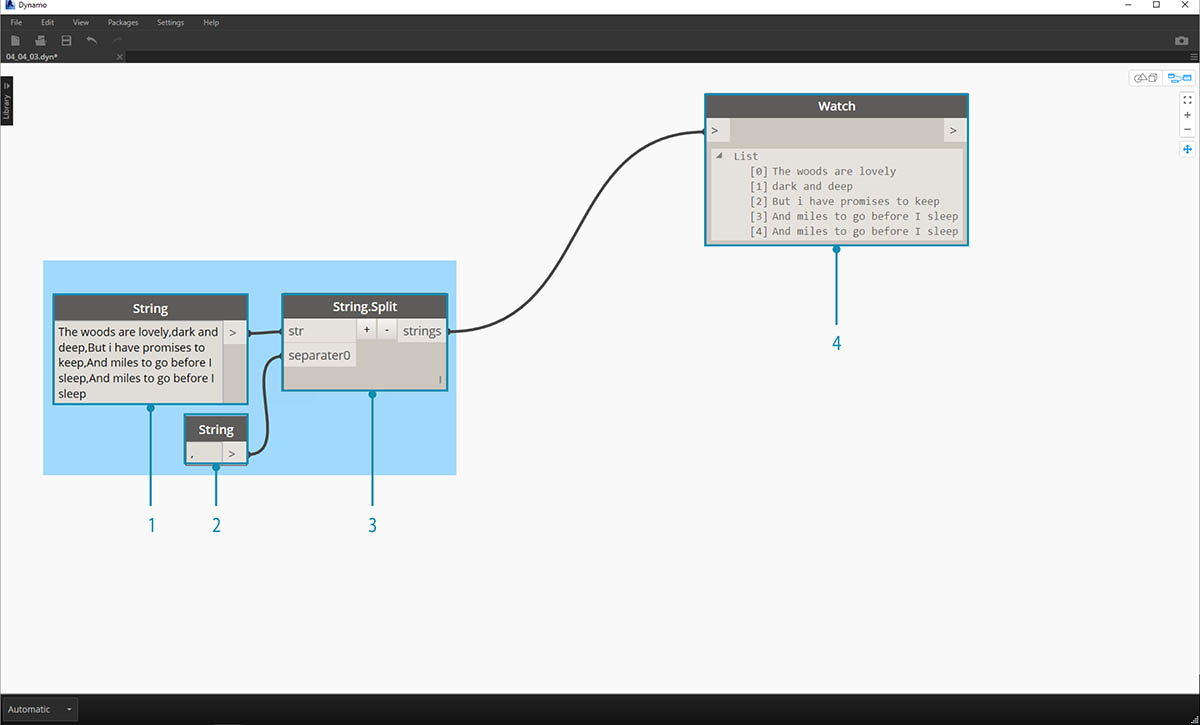
먼저 절의 기본적인 문자열 분할부터 살펴보겠습니다. 작성된 시가 쉼표를 기준으로 형식이 지정된다는 것을 알 수 있습니다. 이 형식을 사용하여 각 줄을 개별 항목으로 구분할 것입니다.
- 기본 문자열이 문자열 노드에 붙여넣어집니다.
- 다른 문자열 노드는 구분 기호를 나타내는 데 사용됩니다. 이 경우에는 쉼표를 사용합니다.
- String.Split 노드가 캔버스에 추가되고 두 문자열에 연결됩니다.
- 출력에 줄이 개별 요소로 구분되었음이 표시됩니다.
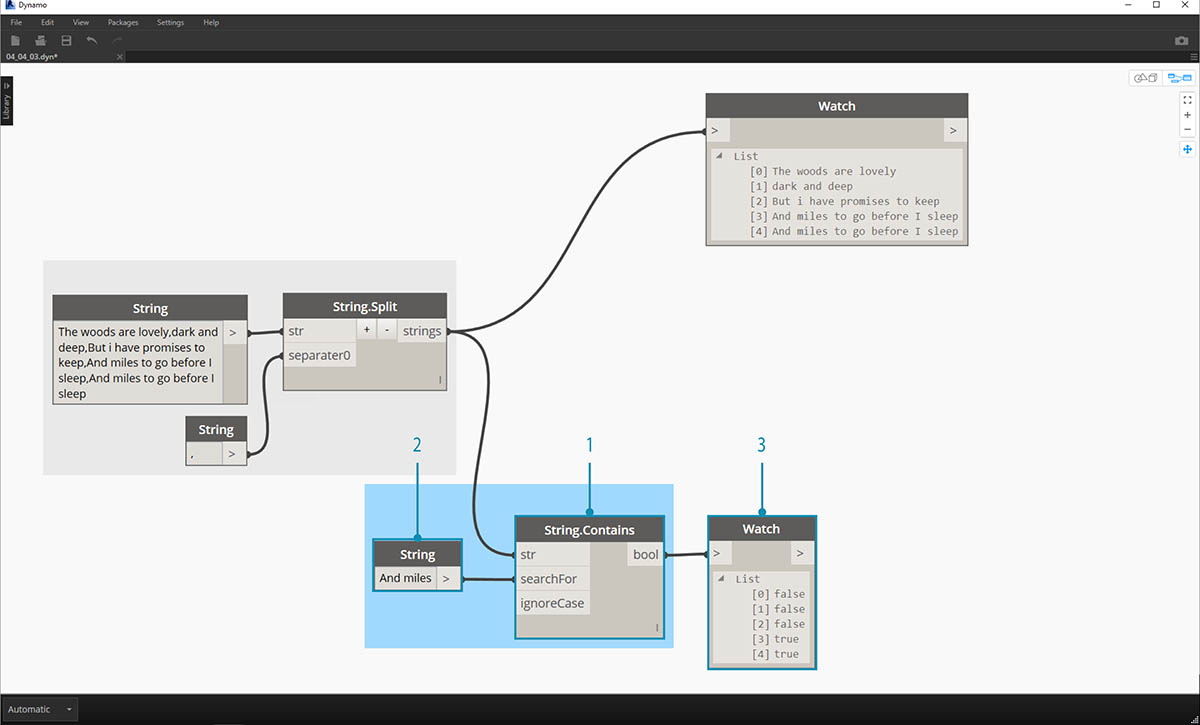
이제 이 시에서 좋은 부분인 마지막 두 줄로 가보겠습니다. 원래 절은 하나의 데이터 항목이었습니다. 첫 번째 단계에서 이 데이터를 개별 항목으로 구분했습니다. 이제 찾으려는 텍스트를 검색해야 합니다. 또한 리스트의 마지막 두 항목을 선택하여 이 작업을 수행할 수 있긴 하지만, 이것이 한 권의 책이라면 모든 내용을 읽고 요소를 수동으로 분리하려고 하지는 않을 것입니다.
- 수동으로 검색하는 대신 String.Contains 노드를 사용하여 문자 세트를 검색합니다. 이는 워드 프로세서에서 "찾기" 명령을 수행하는 것과 유사합니다. 이 경우 항목 내에서 해당 하위 문자열을 찾은 경우 "true" 또는 "false"가 반환됩니다.
- "searchFor" 입력에서는 절 내에서 찾으려는 하위 문자열을 정의합니다. 텍스트가 "And miles"인 문자열 노드를 사용해 보겠습니다.
- 출력에서는 false 및 true 리스트가 제공됩니다. 다음 단계에서는 이 부울 논리를 사용하여 요소를 필터링해 보겠습니다.
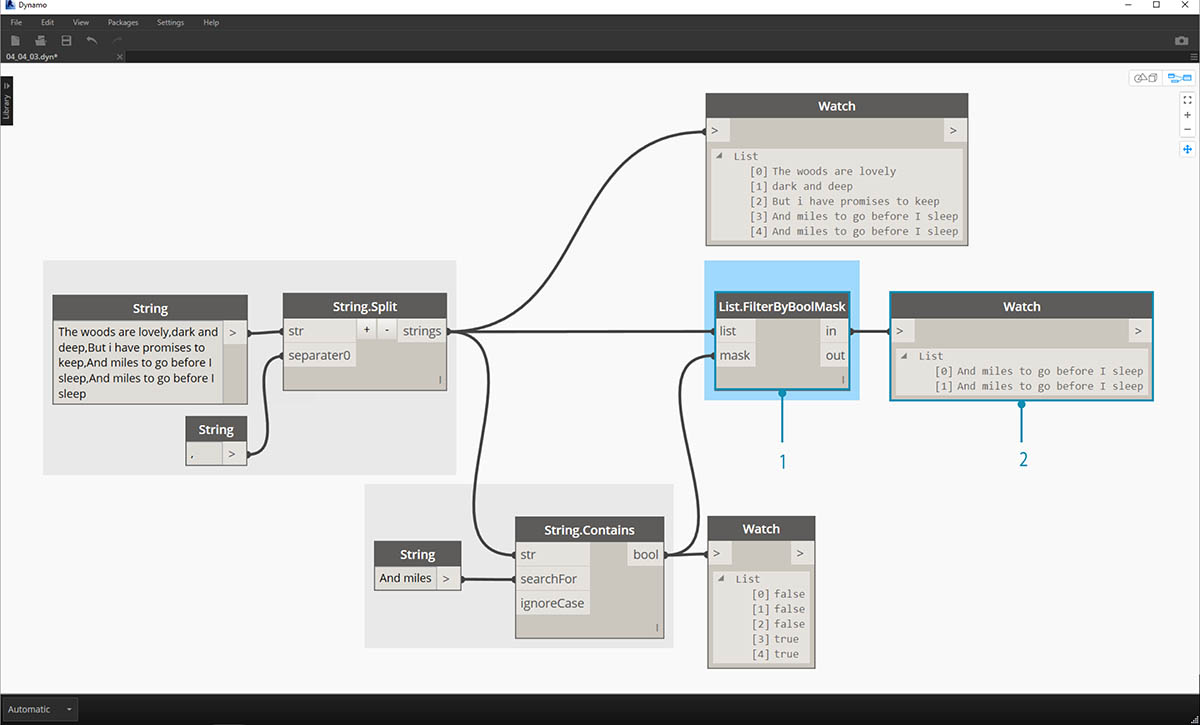
- List.FilterByBoolMask는 false 및 true를 필터링하는 데 사용하려는 노드입니다. "in" 출력은 "mask" 입력이 "true"인 문을 반환하지만, "out" 출력은 "false"인 문을 반환합니다.
- "in"의 결과는 예상한 것처럼 절의 마지막 두 줄입니다.
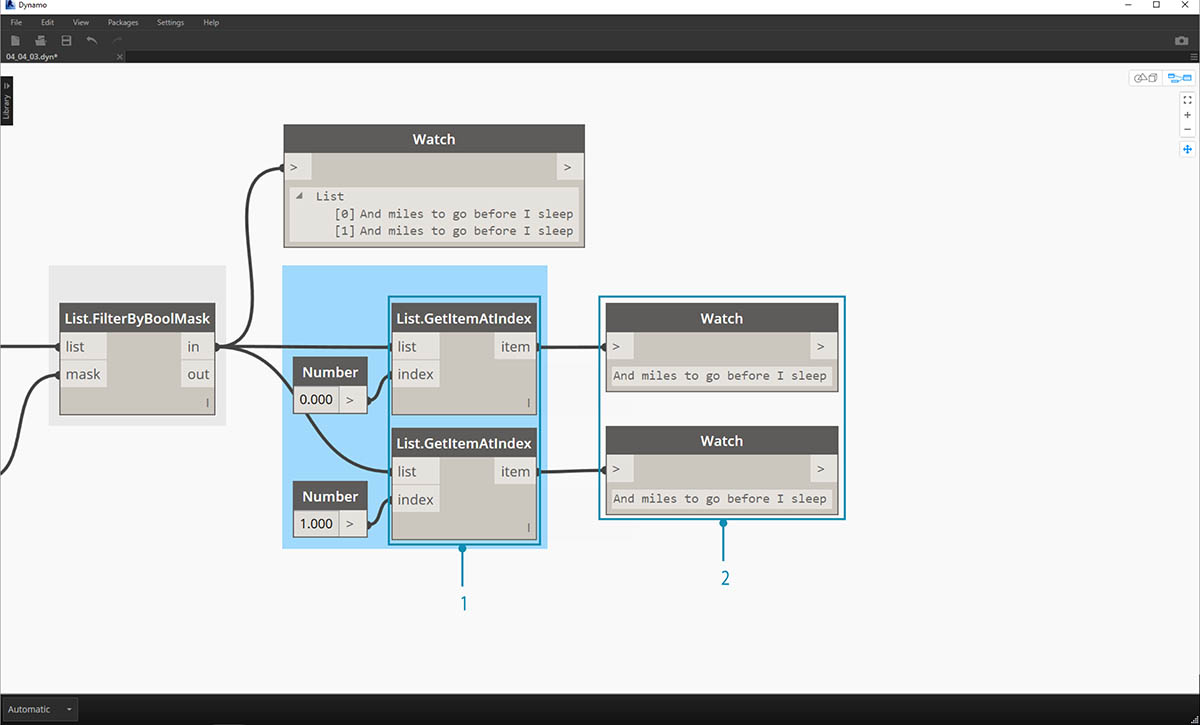
이제 두 줄을 병합하여 절의 반복을 이해하기 쉽게 하려고 합니다. 이전 단계의 출력을 보면 리스트에 다음과 같은 두 개의 항목이 있는 것을 알 수 있습니다.
- 두 개의 List.GetItemAtIndex 노드를 사용하고, 0과 1 값을 색인 입력으로 사용하여 항목을 분리할 수 있습니다.
- 각 노드의 출력에는 마지막 두 줄이 순서대로 표시됩니다.
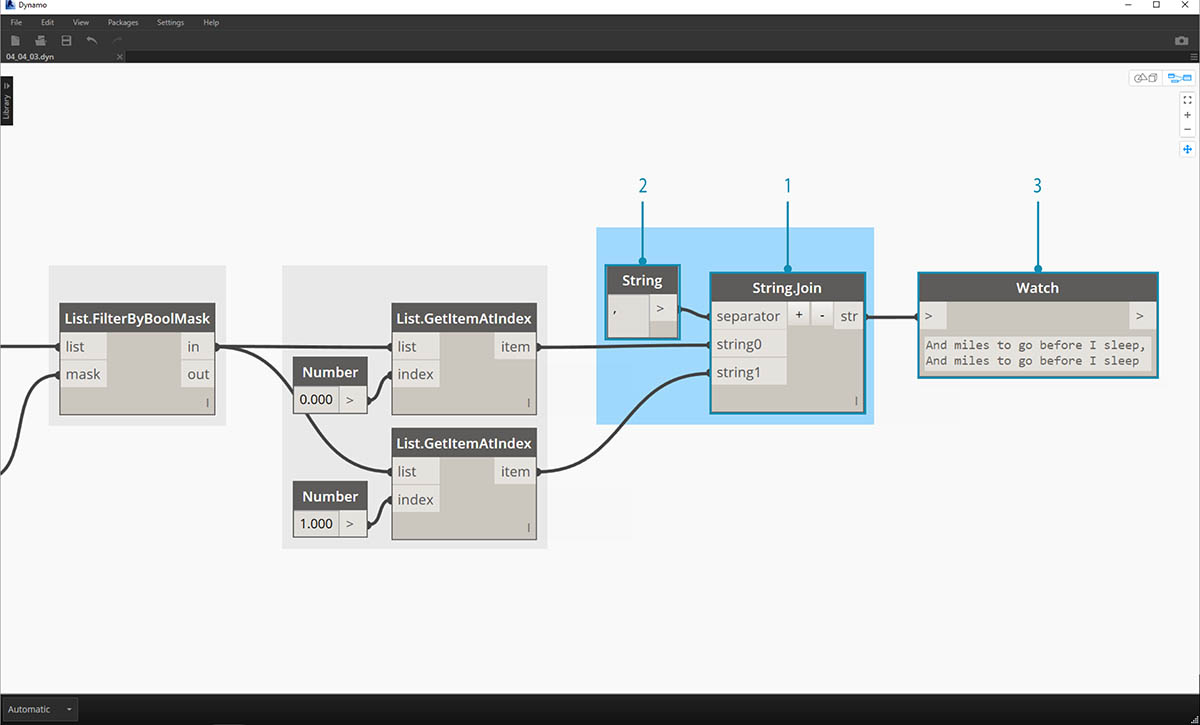
이러한 두 항목을 하나로 병합하려면 다음과 같이 String.Join 노드를 사용합니다.
- String.Join 노드를 추가하고 나면 구분 기호가 필요하다는 사실을 알게 됩니다.
- 구분 기호를 작성하려면 캔버스에 문자열 노드를 추가하고 쉼표를 입력합니다.
- 최종 출력에는 마지막 두 항목이 하나로 병합되었습니다.
마지막 두 줄을 분리하는 데 많은 작업이 필요한 것처럼 보이는데, 이는 사실입니다. 문자열 작업을 위해서는 일부 사전 작업이 필요한 경우가 많습니다. 그렇지만 이러한 작업은 확장 가능하며, 대규모 데이터 세트에 비교적 쉽게 적용할 수 있습니다. 스프레드시트와 상호 운용성을 활용하여 파라메트릭 방식으로 작업 중인 경우에는 문자열 작업을 기억해야 합니다.